“[Users] don’t care about your code—they care about results.”
That’s a controversial statement I found on this dev.to post. It got some virtual stones in the comments from “Clean Code” police officers. I used to be one too. I’ve changed my mind about it.
We don’t write code for the sake of writing code.
We write code to accomplish something for others:
Connecting them with loved ones in the case of Facebook, finding a romantic partner on Tinder, or getting a good and cheap room on Airbnb. Even for boring enterprise software, it’s about happier clients and more sales.
That’s what matters most to the users of Facebook, Tinder, Airbnb, and even boring enterprise software.
The other day, the VP of a software company I was contracting with taught me a lesson about Clean Code and other best practices:
“Clean Code is for us when we have to fix problems and deal with our own mess…users don’t care about that.”
It was a lesson I won’t forget, especially coming from a VP of a software company who had been a coder too.
We write code for humans. For two audiences: our future selves and end users.
Both audiences don’t necessarily intersect. Both audiences don’t care about the same things.
For us and our future selves, it’s about maintaining code quality to add new features and solve bugs.
For end users, connecting with loved ones, finding a romantic partner, getting a cheap room, and keeping clients happy and sales high. They care about what our code could do for them, not about the code by itself. Quality is there to support that mission.
I’ve stayed too long at stagnant jobs, and I regret it.
Staying too long at jobs cost me years and thousands of dollars. I left lots of money on the table. It made some of my skills get rusty.
But after connecting the dots, there were signs I failed to notice:
1. You’re not learning anything new
This is the #1 sign to look for. If your daily job becomes boring, that’s a sign. Or stay but diversify your source of joy.
2. There’s no room for growth
“You can build any role you want,” I was told.
That happened at a past job. I rejected the idea of being a team leader. I didn’t like how the role was designed at that place. It was a “wear all hats for the same pay” role.
And when I brought my ideas to the table, they got rejected with a “somebody else is already kind of doing that.” Staff Engineer? Software Architect? Right Hand? All of them.
It was a red flag I failed to notice.
3. It makes you sick
If your job makes you sick, physically or mentally, what other sign do you need? It’s time to take action. It’s time to run. Run, Forrest, run!
You can always get a new job, but not a new body.
4. You’re learning coping mechanisms
“OK, I just sent a message without a period at the end and without capitalizing the first letter,” my friend told me.
He was working from home and I stopped by for a coffee. In the middle of our conversation, he got a message from work and replied from his phone. There’s nothing wrong with that.
But to make sure his boss didn’t notice it, he didn’t add a period at the end of his message. Oh boy! I had just left that job no more than one year before that.
5. There’s no more money
The last time I heard “There’s no more money this year” when asking for a raise, the Hunger Games of layoffs started, until only a few ones were left standing.
I tried to convince myself I could stretch that job for another year or two. Wrooong! Eventually, layoffs knocked at my door too.
6. You have a bad boss
Often it’s hard to leave work stuff at work when going back home. A bad boss (whatever that means to you) will make you feel bad along with the people around you.
7. There’s no willingness to change
If after raising flags with your boss, you only hear “that’s fine. It used to be worse” or anything along those lines, that’s where change dies. Don’t waste more time bringing ideas.
Either you accept things the way they are or disagree with your feet.
8. It’s more important to find who to blame
If something goes wrong, it means there’s a flaw in a standard procedure or a process that let it happen. Finding who to blame only create a toxic work environment. Don’t waste time blaming. Fix the process.
I put on my creator’s glasses and watched Six Triple Eight, a Netflix movie about the only battalion of American Black women in Europe during WWII.
Here are the storytelling devices I noticed:
#1. The story starts somewhere in the middle, not at the beginning of the events. It starts with a scene of a plane being shot down in the middle of WWII. Then, it takes us back to the days before that incident and builds from there.
#2. This battalion ran the mail operation for the troops in the frontlines. So we follow a letter covered with blood from the first scene all the way throughout the movie.
#3. Apart from delivering letters, it tells us other stories:
The story of Major Adams, the officer in charge of the battalion. Based on a real character.
The discrimination Black women faced inside the Army.
Lena, our protagonist, falling in love with the pilot from the first scene.
#4. It follows the problem/tension/climax/resolution technique:
It starts with the battalion facing an impossible mission (delivering the mail)
Being Black women in the Army, nobody believed in them.
They completed the mission ahead of time.
They earned the respect of the people who used to bully them.
#5. The entire story is told from the point of view of a single woman, Lena, our protagonist. Based on a real character too.
#6. Like any other movie inspired by real events, it wraps up with the real footage of the real Six Triple Eight battalion entering in Europe.
#7. The movie starts with a love story and ends with another love story. It ends the same way it started.
Oh, boy! It took me like 3 hours to figure this out.
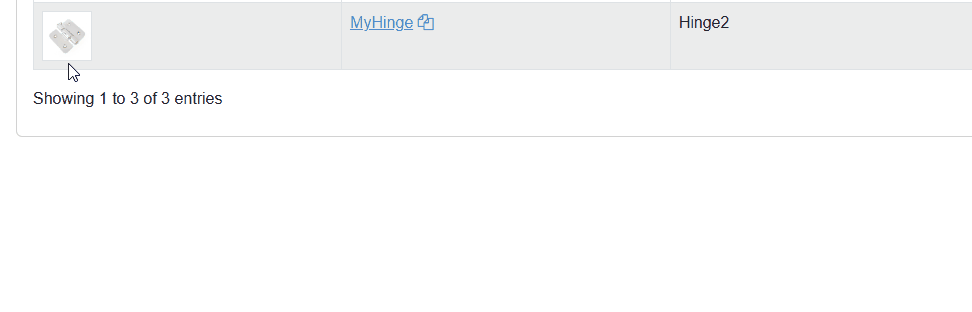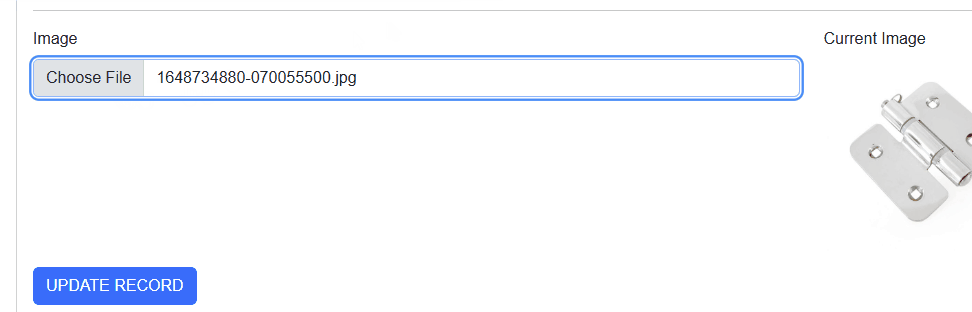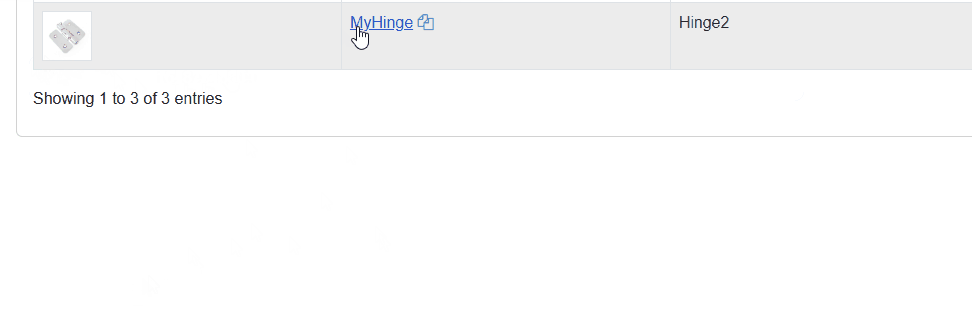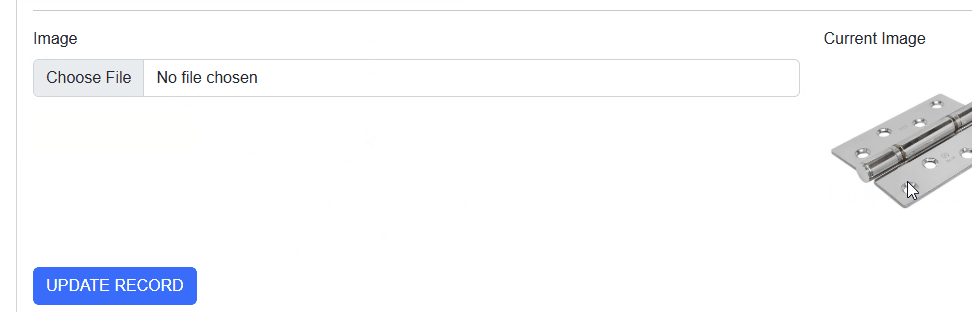
Here’s the thing: I had a CRUD app with Blazor. In the Update page, I could change images—let’s say, a hinge and other parts used to build a closet. Nothing fancy.
The problem?
After updating the image and redirecting back to the List page, it still showed the previous image. Whaaat?! The API endpoint did update the image.
Since I can’t show you the real code, for obvious reasons, here’s a little corner of the app,
After updating my image, it still showed the old one. Arrggg!
It only worked after pressing F5, to reload the entire page.
I tried to solve it by forcing a reload when redirecting from the Update page back to the List page. Like this,
But sometimes it still showed the old image. Arrggg!
After googling for a while, this SO answer saved my day. It was the browser trolling me all that time.
OK, the API endpoint powering the List page returned a public URL of every image, served from the same server. Every image file was named after the related object ID, something like /public-files/acme-corp/my-cool-object/123.png
Even though the backend changed the images, their URLs were the same. And the browser didn’t notice anything new, so it kept showing the same image, without requesting it from the server.
The solution?
Append a timestamp to every URL. Audit fields are helpful here…I ended up appending the modification date of every image. Like this,
In fact, this is my post number 322. Over five years ago, I wrote my first post. Well, “post” is a strong word. It was a word vomit. I still keep my first post unedited to remind me how I started.
I only wrote when I thought I had something to say. It was once every full moon when I started. Then it was every other week. Since Nov 1st, 2024, I’ve been doing it daily. I already passed the 100 daily posts mark. My next goal: the 200 mark.
All that to say, I’ve learned a thing or two about blogging and writing. Mostly, after lots of trial and error. And if you’re starting out, here are 10 quick tips for you:
#1. Write descriptive headlines: “How to do X with Y in order to Z” works perfectly fine for most of your posts, technical or not. Or steal your headlines, like an artist.
#2. Ditch long intros: Go straight to your main point. Don’t worry about introductions at the beginning. I wanted to jump straight to #1 in this post. But in a moment of inspiration, I wrote that introduction to “prove” I know what I’m talking about.
#3. Start with a 1-sentence paragraph: OK, if you decide to write introductions, start your posts with one sentence. Imagine your first line is like an extra headline. See what I did in this post. I learned this trick from my first writing class.
#4. Use subheads: Use h2 and h3 tags to break your post into parts. These tags help readers skim and digest your post. And this helps SEO bots understand your post. If you’re writing a how-to guide, use one subhead for every step/lesson/point of your post…You know what, I could have used one h2 tag for every point in this post.
#5. Write shorter paragraphs: Shorter paragraphs and sentences make your posts easy to digest.
#6. Use simple words: A post isn’t a New York Times column or a school essay where you’re chasing an A+ or a 10.
#7. Deliver your message fast: It goes hand in hand with #2. Your headline is a promise. Fulfill your promise in your post body. If you’re writing how to fix the air conditioning of your car, tell that in your post. Don’t go on tangents. Leave those tangents to write more posts. Give something and give it fast.
#8. Avoid meta sentences: I blame writing in schools and their mantra: “tell readers what you’re going to tell them, tell the thing, then tell what you just told them.” Arrggg! Don’t do that. Don’t write “now, let’s cover how to…” or anything like that. I used to do that after every section. See #7.
#9. Write for 1 person: Next time you sit down to write, picture yourself explaining it to only one person: a friend, a coworker, or even your dog. It will give you the right tone to use and the right points to cover in your post. For example, again if you’re writing about how to fix the air conditioning of your friend’s car, you don’t have to explain what a car is to him. He already knows it.
#10. Avoid summary-like conclusions: Ditch conclusions the same way you ditch intros. And please avoid regurgitating everything back in a conclusion. Instead, ask your readers to do something after reading your post or promote other posts. Again see #2, #7, and #8.
I could give you more tips on SEO, but let’s keep it like that. If you followed these tips, especially #1 and #4, search engines will like you. Search engines love when we write for humans.
Keeping a blog helped me skip hiring lines the last time I was looking for a job. I showed my blog during the interview and the process went faster from there. No more rounds of interviews after that.