I bet you have heard the news about layoffs in the tech industry. They’re so common these days that there’s even a page out there to report and track them. Some days ago, I got a message from a close friend who was laid off. Personally, I’ve been there. I know how it feels. These are some of the lessons I’ve learned on layoffs I shared with her.
1. Job security is an illusion
I don’t know who makes us believe there’s such a thing as “job security.” That’s an illusion.
In my early days at college, I thought the safest route was being an employee. I was so wrong! I only needed being laid off once to change my mind.
We could lose our jobs anytime for reasons we don’t (and can’t) control: a pandemic, a company going bankrupt, or a recession.
The real question is when it will happen, not if it will ever happen to us. We’re better off preparing for that.
An emergency fund is enough savings to cover our essential expenses for some time. The longer, the better. That would give us enough breathing room until we land in another place.
An emergency fund could be the difference between being picky about the next job or accepting anything to pay the bills.
3. Always be ready
Let’s always have our CVs ready and keep in touch with our colleagues. Let’s not wait for a layoff to have an online presence. That would be too late.
Let’s always be ready for an interview. Interviewing is broken, I know! But let’s always be ready to leave.
Voilà! Those are my thoughts about layoffs. I learned that after losing a job, there’s always a positive change. That takes us out of our comfort zone. “Pastures are always greener on the other side,” I guess.
These days I reviewed a pull request in one of my client’s projects and shared a thought about reading database entities and layering. I believe that project took layering to the extreme. These are my thoughts.
For read-only database-access queries, reduce the number of layers in an application to avoid excessive mapping between layers and unneeded artifacts.
Too many layers, I guess
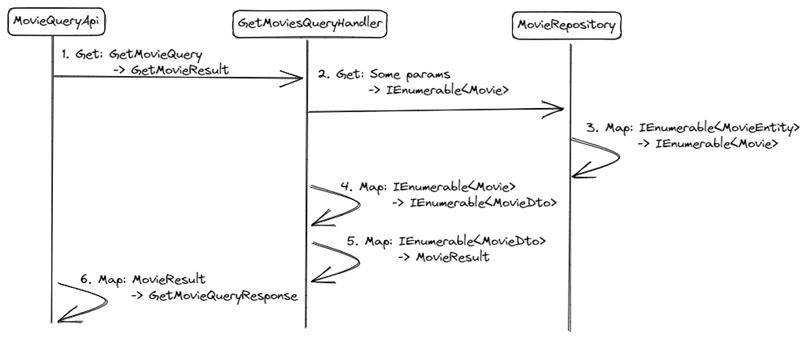
The pull request I reviewed added a couple of API endpoints to power a report-like screen. These two endpoints only returned data given a combination of parameters. Think of showing all movies released on a date range with 4 or 5 stars. It wasn’t exactly that, but let’s use that example to prove a point.
That project had database entities, domain objects, results wrapping DTOs, and responses. To add a new read-only API endpoint, we would need a request object, query, query handler, and repository.
Inside the repository, we would need to map database entities to domain entities and value objects. Inside the query handler, we would need to return a result object containing a collection of DTOs. Another mapping. Inside the API endpoint, we would need to return a response object. Yet another mapping. I guess you see where I’m going.
This is the call chain of methods I found in that project:
Three layers and even more mappings
And these are all the files we would need to add a new API endpoint and its dependencies:
That’s layering to the extreme. All those artifacts and about three mapping methods between layers are waaay too much to only read unprocessed entities from a database. Arrrggg! Too much complexity. We’re only reading data, not loading domain objects to call methods on them.
I believe simple things should be simple to achieve.
For read-only queries, the HODDD book uses two models:
Query Models for the request parameters, and
Read Models for the request responses.
Then, it calls the underlying storage mechanism directly from the API layer. Well, that’s too much for my own taste. But I like the simplicity of the idea.
I prefer to use Query Services. They are query handlers that live in the Infrastructure or Persistence layer, call the underlying storage mechanism, and return a read model we pass directly to the API layer. This way, we only have two layers and no mappings between them. We declutter our project from those extra artifacts!
We put the input and output models in the Application layer since we want the query service in the Infrastructure layer. Although, the HODDD book places the input and output models and data-access code directly in the API layer. Way simpler in any case!
Voilà! That’s my take on read-only queries, layers, and Domain-Driven Design artifacts. I prefer to keep read-only database access simple and use query services to avoid queries, query handlers, repositories, and the mappings between them. What do you think? Do you also find all those layers and artifacts excessive?
Some days ago, I got a message from someone starting his journey to become a Software Engineer. He found my post with the takeaways from the Ultralearning book and asked for feedback.
On the email, my reader explained that he wanted to become a professional Software Engineer with a one-year ultralearning project. Also, he wrote he had a list of resources compiled and already made some progress.
I want to document my reply to help others and preserve my keystrokes. This is my long reply:
Set milestones: Keep yourself focused and motivated with milestones. For example, after 2 or 3 months of studying, make sure to complete an introductory CS course or have some features of a coding project ready. Often we underestimate what we can do in a year or get easily distracted.
Choose Math subjects wisely: This might be controversial. But don’t get too focused on learning advanced Math. Depending on the business domain you’re working on as a Software Engineer, you might not need a lot of Math. Unless you’re working on Computer Graphics, Finance, or Simulations. I’d stick to courses on Linear Algebra and Math for Computer Science.
Use roadmaps: Find list of subjects to learn from roadmaps. If you search on Google or GitHub “programming roadmap <insert year here>,” you will find good resources. But you don’t need to learn all those subjects at once. Instead, understand how a particular subject or tool fits into the larger picture and when you need it.
Write an end-to-end coding project: Write a coding project that reads data from a webpage, calls a backend, persists data into a relational database, and displays it back. You will learn a lot from this simple exercise. HTML/CSS, a UI library, HTTP/REST, a backend language, SQL, and a database engine. Quite a lot!
Be consistent: Set a regular study time and put it in a calendar. I find the green squares on my GitHub profile inspiring to keep myself in the loop.
Learn the tech and tools companies are hiring for: Probably, you will hear or read people arguing to learn X instead of Y or X pays more than Y. Instead, use a more tactical approach, find what companies around you (or on LinkedIn) are looking for, and learn those subjects.
Keep a journal: Keep track of what you learn, the resources you use, and the subjects you find challenging. You don’t need anything fancy. A simple .txt file works. I found this advice on “Never Stop Learning” by Bradley R. Staats.
Voilà! That’s how I would approach a ultralearning project to become a Software Engineer. My last piece of advice is you don’t need to learn everything at once. In the beginning, learn a handful of tools and learn them well. But don’t be afraid of learning something else. Later you could start expanding your toolbox and finding what you like the most.
I wrote my own roadmap for intermediate C# developers. It points to C# resources, but its overall subject structure works for other languages too. This is not for absolute beginners.
I tried to challenge myself with mini ultralearning projects. I choose to learn enough React and Go in 30 days.
Some days ago I found out this Hacker News question about what blogging has done for blog writers. I realized that I published my first blog post five years ago. I’d like to share what blogging has done for me.
In a past post, I shared how I started blogging and the story behind my first post. Long story short: I didn’t want to throw away some hours of Googling.
1. What has my blog done for me?
I wish I could tell that I could live out of my blog. That’s not the case yet. But it had opened doors here and there.
After sharing some of my posts on my LinkedIn profile, I got an invitation to create text-based programming courses on a new teaching platform. I wrote a couple of C# courses there.
Again from LinkedIn, someone from the Marketing team of a software company reached out to me for a content collaboration. I wrote two sponsor posts here on my blog and others on its company blog.
On another occasion, an acquaintance set me up for an interview for a full-time opportunity as a software engineer. I declined it, but that interview ended up being another content collaboration. I helped that company to start a Medium publication.
Apart from content collaborations, keeping a blog made learn two skills: online writing and SEO.
I haven’t updated my first post. It’s right there to remind me how I started. At the time, I had zero experience writing online. I only threw some words into an empty file and put it online.
I had to learn to use shorter sentences, descriptive subheadings, and clear structure.
I learned to target my posts to a user search query. Also I learned to distinguish between posts I want to rank and posts where I share some thoughts. This is one of them.
I stopped writing about whatever came to my mind to follow a topic over a series of posts regularly.
3. Sources of inspiration
In all these years, I have received inspiration from others in the process.
The book Show Your Work by Austin Kleon inspired me to keep writing. Not only do the end results matter, the process to get there, too. I learned that from the book.
I follow the mantra: “If something takes you more than 20 minutes to figure out, it should be a post.” I learned that from a YouTube video, I can’t find any more.
4. Some of my favorite and popular posts
In these five years, I’ve written 152 posts, to be precise. Some blog posts came from my frustrations, curiosity, and learning. Often, I like to think of my blog as my own time capsule and a tool to preserve my keystrokes.
Parsinator: A tale of a PDF parser: This is about Parsinator, a small project I wrote in record time to keep one of my previous employers onboarding new clients.
A quick guide to LINQ with examples: I wrote this one to help a friend. She was preparing for a technical interview. This is an “all you need to know” post. I ended up expanding it into a full series of posts and a text-based course.
Unit Testing 101: This is one of the guest posts I originally wrote on exceptionnotfound.net. I expanded it to a whole series of posts about unit testing.
This is another episode where I share the talks from NDC Conference I watched and liked. This time is about JavaScript, History, and Design.
How JavaScript Happened: A Short History of Programming Languages - Mark Rendle
This is a journey from FORTRAN to ALGOL to LISP to JavaScript. It explains why we still use if for conditional, i for loops, and * for multiplication. Spoiler alert: It’s because of FORTRAN.
Apache Kafka in 1 hour for C# Developers - Guilherme Ferreira
Clusters, Topics, Partitions, producers/consumers? This is a good first-time introduction to Kafka. The presenter uses kafkaflow and confluent-kafka-dotnet for the demo application.
Keynote: Why web tech is like this - Steve Sanderson
I found this one on r/programming (before the Reddit blackout) Informative! It feels like time traveling through operating systems and tools to create a Web page.
Pilot Critical Decision Making skills - Clifford Agius
The lesson from this one is to come up with a list of things that could go wrong and prepare and train for that. Follow TDODAR approach: Time, Diagnosis, Options, Decision, Assign, and Review.
Intentional Code - Minimalism in a World of Dogmatic Design
I like the idea that “software really is literature.” Not in the sense of literate programming but in the sense of a narrative to express idea where every line of code matters. I like the example of how a piece of code improves by only removing a few blank lines.
Another idea I liked is: “You don’t want everything to look the same.” We don’t want all applications to use Domain-Driven Design with Event Sourcing and microservices. Often architectural patterns only add to cognitive load and extra complexity.
The presenter suggests: “sitting and looking at it (at a piece of code) and working out how it makes you feel. And then when you feel something, try to understand why it feels that way.”
Voilà! Another Monday Links. What tech conferences do you follow? Do you also follow NDC Conference? What are your favorite presentations? Until next Monday Links.